
This tutorial deeply covers the SELECT statement of the T-SQL/SQL language. Starts from the basics - how to retrieve the values inside a column to ordering data, selecting multiple columns and then tables, joining them...
What you will need for this tutorial:
- Microsoft SQL Server 2000 any edition (even MSDE)
- Microsoft SQL Server Enterprise Manager
- Microsoft SQL Server Query Analyzer
The Northwind database (along with the pubs database) is included in any SQL server installation, except for MSDE (Microsoft SQL Server Desktop Engine). So if you don’t have this database you can download an utility from MSDN which, if you run it, will install the two databases.
Using the SQL Query Analyzer
The SQL Query Analyzer is a tool where you can test your queries on the available databases. When you start the application you’ll be asked to select a SQL Server and the authentication mode.
If you don’t see any server name in the list click the ‘…’ button and select a server from that list:
I recommend you select ‘Windows Authentication’.
A query window is started but first a database on which the query will be executed must be selected. You can select a database from the toolbar on the top:
Select the Northwind database because this is the one we’re going to use in this tutorial.
Using SELECT
Selecting a column
The SELECT command is the single keyword of DQL (Data Query Language – one of the categories in which T-SQL is divided).
Using this keyword you can retrieve data from the database. Let’s test it a bit using Query Analyzer.
In the query window use the following query to retrieve a column (CategoryName) from a table (Categories):
| SELECT CategoryName FROM Categories |
Note that the keywords ‘select’ and ‘from’ are written all uppercase. This is not a requirement, more like a habit.
Now run this query by pressing F5 or clicking the ‘>’ shaped button (or play) from the toolbar. The result is the following:
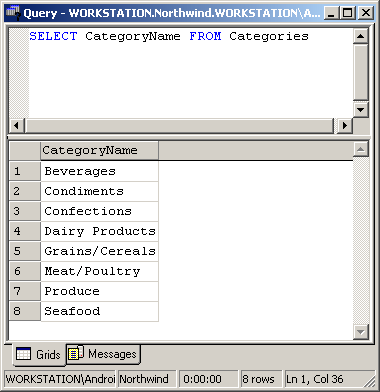
As you probably notice, the query we executed returns the contents of the CategoryName column from the Categories table.
If you didn’t yet get it (although I think you did), here’s how the query works:
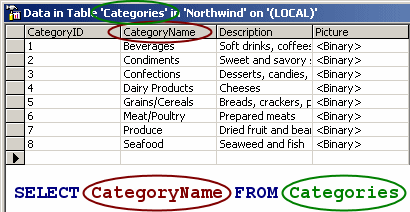
This is a screenshot of the entire Categories table viewed with SQL Server Enterprise Manager.
Well, I think you realized from the first view what the query ‘SELECT CategoryName FROM Categories’ does. No wonder, as if you look in a dictionary for the term SQL you’ll find something similar:
computer language: a standardized language that approximates the structure of natural English for obtaining information from databases.
Full form structured query language
Microsoft® Encarta® Reference Library 2003. © 1993-2002 Microsoft Corporation. All rights reserved.
If this query could be more obvious probably it would sound like ‘Select the CategoryName column from the Categories table’.
Selecting multiple columns
You can select multiple columns from a table by separating their name with a comma:
| SELECT CategoryName, Description FROM Categories |
The result being the following:
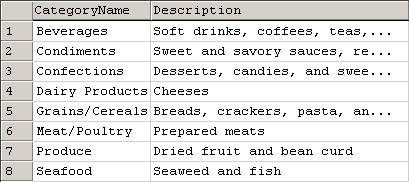
Selecting all columns from a table
Sure, you can select all the columns from a table by specifying each column name, the way we saw earlier in Selecting multiple columns. But there’s another way, a shorter one:
| SELECT * FROM Categories |
This can be translated in english like ‘Select all from categories’. So it retrieves all the columns from that table without having to specify each one of them. It’s well known that the * (asterisk) sign is often used in such cases.
Selecting only values that meet a criteria
Often when retrieving data from databases you need to return only values that meet a particular criteria. In our Categories table perhaps you may want to retrieve the description (available in the Description column) of a specific product, let’s say of Condiments.
You may think you can retrieve all the values from that table and then, in your application, search for the one that is equal to ‘Condiments’. That would be – pardon me – stupid!
Stupid, because you can retrieve only the value you are interested in by specifying this in the query, which is way more efficient:
| SELECT CategoryName, Description FROM Categories WHERE CategoryName = ‘Condiments’ |
This can be translated like “Select from the table Categories the value in the column CategoryName that is equal to ‘Condiments’. Also select the description for that item”.
Here you can see the result:
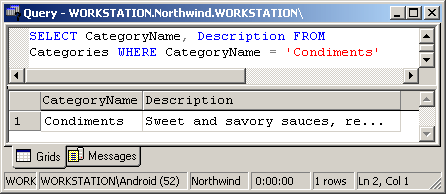
Selecting only values that meet more than one criteria
In SQL Server Enterprise Manager, still in the database Northwind, open the table Customers where you’ll see lots of fictive company names, contact names and titles, cities, countries etc.. On ContactTitle column you can see many ‘Owner’ values. Of course, if you want to select only the people who are owners, you would do a “SELECT * FROM Customers WHERE ContactTitle = ‘Owner'”. Still, you want to find all the owners from Mexico. That’s not hard at all:
| SELECT * FROM Customers WHERE ContactTitle = ‘Owner’ AND Country = ‘Mexico’ |
As you can see, the result is composed from 3 values. These 3 all are owners and live in Mexico. We retrieved this with the help of the AND keyword.
Sorting results
Using SQL you can sort results ascending on descending. When sorting numbers ascending means from 0 up to 1, 2, 3 and so on, and of course, sorting descending is the reverse (ex. start with 56, continue with 55, 54, 53…). When sorting by letters, ascending means you start from A and end with Z, and descending means you start with Z and end with A.
So, how do I actually sort?, you ask. Suppose you want to sort the values inside the Customers table ascending, by the name of the country:
| SELECT * FROM Customers ORDER BY Country ASC |
The list starts with Argentina and ends with Venezuela.
Selecting distinct values
In a table, for some obscure reason, you have duplicate records. Let’s take the table we’re currently working with – Customers. You want the list of all the countries where you have customers in. If you would just return all the countries as they are in the database you would get ‘Argentina, Argentina, Argentina, Austria, Austria, Belgium, Belgium…’ …you get the point. There are no three Argentina’s but there are 3 customers in that country, so for each one its country is returned. Here’s where the DISTINCT keyword helps you out:
| SELECT DISTINCT Country FROM Customers |
So now duplicate values are eliminated and you’re happy cause you get the list of countries without duplicates.
Selecting with another criteria if the other didn’t met
Maybe you want to retrieve all the customers from Liechtenstein, but if there are no customers there, you want to retrieve the customers from Switzerland. You can do this using the OR keyword:
| SELECT CompanyName, Country FROM Customers WHERE Country = ‘Liechtenstein’ OR Country = ‘Switzerland’ |
In the table there’s no customer from tiny Liechtenstein but there are two from Switzerland, therefore these will be displayed.
Selecting data from multiple tables
Most of the time when doing SQL queries you’ll have to work with multiple tables.
Think about this: you have a table where you store your employees and one where you store the orders. Obviously, every row / field in the orders table represents an order. Each order has an employee who’s responsible for it. Sure, for every order in the orders table you can specify the employees name, title, phone, address, hire date… But employees usually manage tens of orders, so to include all the employee information for each order is ineffective.
If you don’t know already how this kind of stuff is done right with most databases, here it is:
In the employees table, each employee has an unique ID. In the Northwind databases, Davolio Nancy has ID 1, Fuller Andrew has ID 2 and so on… So why don’t we just store this number instead of the name in the orders database. If one order is handled by Fuller Andrew, we’ll store his id which is much shorter than storing all the information again and again for each order. Let’s see how this works:
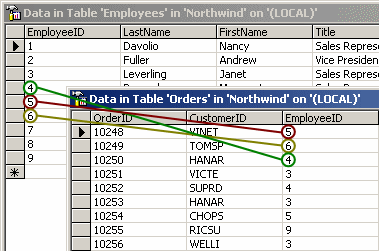
Using JOIN
INNER JOIN
Now, how can we join this two tables so that when we want to return information about an order, to have the name, title and phone of the employee that handles the order… to look like they’re all in one database? Using JOIN.
Run the following query:
| SELECT LastName, FirstName, Title, ShipAddress FROM Employees INNER JOIN Orders ON Employees.EmployeeID = Orders.EmployeeID |
And see the result:
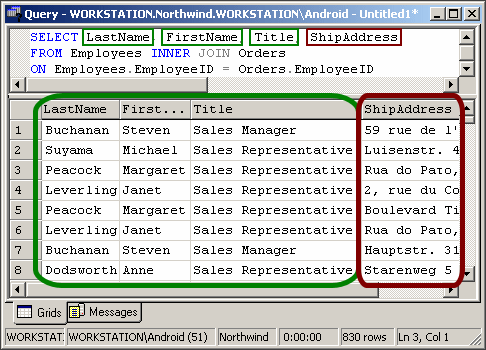
We joined two tables by specifying something that they have in common: the employee ID. LastName, Firstname and Title (in green) are columns from the Employees table and therefore provide information about the employee who’s responsible for the order. ShipAddress (in red) is from the Orders table.
So what does our query say?
“Select the columns LastName, FirstName, Title and ShipAddress from the table Employees and the table Orders where there is a match between the values in column EmployeeID from the Employees table and between the EmployeeID column from the Orders table.” – that’s what our query says.
OK, you say, I understand that the JOIN keyword is used to join two tables using columns with ID’s, but what’s the role of the INNER keyword (in INNER JOIN)? By specifying INNER, only the rows that match are displayed. For example if in the Orders table there’s one order that says it’s being handled by employee ID 10 but inside the Employees table there is no Employee with ID 10, the order won’t be displayed as it doesn’t have a match in the Employee table.
There are other types of JOIN (FULL OUTER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, CROSS JOIN).
LEFT OUTER JOIN and RIGHT OUTER JOIN and FULL OUTER JOIN
As we discussed earlier, using INNER JOIN, the values that don’t have a match aren’t shown.
Using LEFT OUTER JOIN the situation is different. Let’s take our case with the Employees and Orders tables and run this query:
| SELECT LastName, FirstName, Title, ShipAddress FROM Employees LEFT OUTER JOIN Orders ON Employees.EmployeeID = Orders.EmployeeID |
This query acts exactly like the earlier one, so it joins two tables. But because instead of using ‘INNER JOIN’ we used ‘LEFT OUTER JOIN’ if there is one value (more exactly ID) in the Employees table that doesn’t match the value / ID in the Orders table, it will still be displayed.
For example I add a new employee named Art Vandelay with the title of CEO in the Employees table. Next I run the query shown above. What do we see if we scroll down to the bottom of the list? Even if there’s no order handled by Art Vandelay inside the Orders table (maybe he’s too lazy or he’s recently hired), a row with LastName, FirstName and Title will still be shown. Of course, we don’t have the value for ShipAddress because this is a column inside Orders table where, as I stated earlier, there is no match:

So the ShipAddress value is set to NULL.
The difference between LEFT OUTER JOIN and RIGHT OUTER JOIN is simple. While in LEFT OUTER JOIN the rows from the table specified in the FROM clause will still be displayed even if they have no match, in RIGHT OUTER JOIN the rows from the table not specified in the FROM clause will still be displayed, even if they don’t match with the values in the other table, therefore the one specified in the FROM clause will have nulls.
So if you have an order handled by employee ID 23 (which doesn’t exist in the Employees table), the order will still be shown but with the employee information set to null.
FULL OUTER JOIN works as you might expect, even if there’s no match between neither one of the values in the two tables, the values will still be displayed… this is actually LEFT OUTER JOIN + RIGHT OUTER JOIN.
Specifying the table in which the column is
Let’s take the first query we used to join two tables:
| SELECT LastName, FirstName, Title, ShipAddress FROM Employees INNER JOIN Orders ON Employees.EmployeeID = Orders.EmployeeID |
After the ON keyword, we specify the table from which we want the EmployeeID column, as both tables contain a column with this name… think at it, it wouldn’t make sense to say ‘…ON EmployeeID = EmployeeID’, the computer wouldn’t know at what EmployeeID column you refer to.
This case also applies to the column names after the SELECT keyword – LastName, FirstName, Title, ShipAddress. What if in the Orders table you also had a column named Title? How is the computer supposed to know which one you want to select? How are you supposed to know what column you want to select when looking at your code after a few months?
In conclusion, always prefix the name of the columns with the name of the table even if there are no columns with the same name in the two tables, because you may add later. So here’s how it should be:
| SELECT Employees.LastName, Employees.FirstName, Employees.Title, Orders.ShipAddress FROM Employees INNER JOIN Orders ON Employees.EmployeeID = Orders.EmployeeID |
Using UNION
Suppose you have two tables of employees (for some obscure reason), one named oldEmployees and the other newEmployees. You’ll want to join them so you can see all the employees your company has. You can do this using the UNION keyword, and the query is straightforward:
| SELECT FirstName, LastName FROM oldEmployees UNION SELECT FirstName, LastName FROM newEmployees |
This will combine the columns of the two tables. Beware that you have to specify the same number of columns in the first SELECT statement as in the second SELECT statement. Also note that the columns need to have the same type (both varchar for example).
If the name of one employee is listed in both tables (which frequently happens with first names and last names), only one will be displayed. This can be changed by using UNION ALL instead of UNION.
There are some small things I didn’t cover here, like CROSS JOIN, which I don’t consider very important.
If this tutorial is appreciated other SQL tutorials will follow (on using INSERT, UPDATE, DELETE and more advanced topics). Oh, and feel free to comment on this tutorial.


